윈도우에서 openAI Gym을 이용해서 슈퍼마리오 AI 플레이 만들기
1. 윈도우 서브시스템 리눅스에 openAI Gym 설치하기
http://jinman190.blogspot.ca/2017/10/openai-gym.html
2. openAI gym을 이용해서 슈퍼마리오 설치해서 자동 플레이 하기
http://jinman190.blogspot.ca/2017/10/openai-gym_14.html
3. 슈퍼마리오에 모두를 위한 RL 수업의 딥러닝 코드 붙이기
지금 여기
4. 슈퍼마리오의 딥러닝 코드 효율적으로 고쳐보기
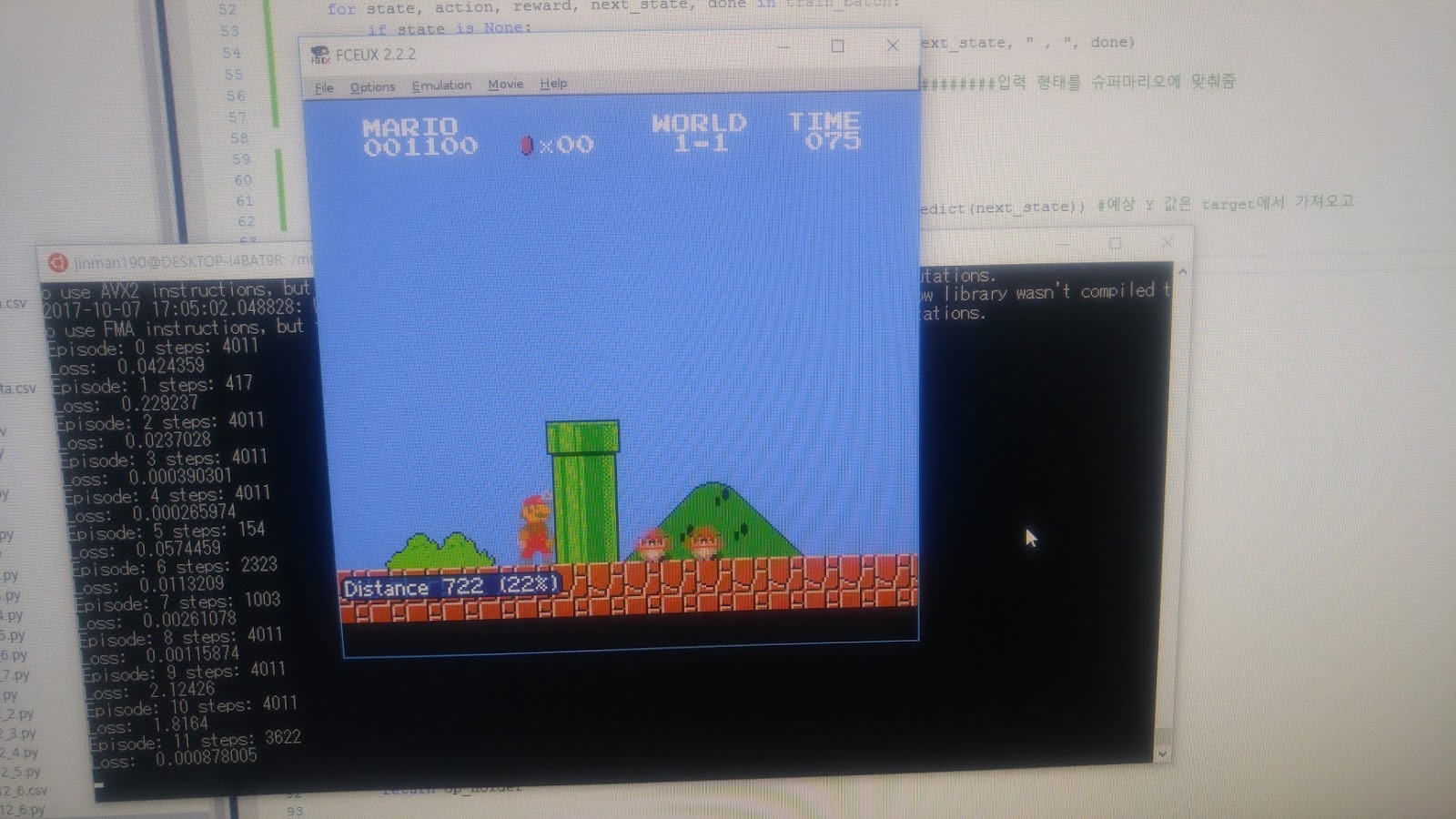
목표: 모두를 위한 RL 수업에서 쓰인 코드로 슈퍼마리오를 실행 해 보려고 한다.
(효율적인 딥러닝을 하는게 아니라 우선 변수 차원 맞춰서 에러없이 실행만 해보기)
Sung Kim 교수님의 모두를 위한 RL 수업은 여기.
https://www.youtube.com/playlist?list=PLlMkM4tgfjnKsCWav-Z2F-MMFRx-2gMGG
코드는 여기서 받았다.
https://github.com/nalsil/kimhun_rl_windows/blob/master/07_3_dqn_2015_cartpole.py
알아내느라 꽤 걸렸는데 실제로 고친건 몇줄 안된다.
최종 코드 파일은 여기:
https://docs.google.com/document/d/16LLmgRPGZF2-wEa57uSbvwhDlnaPgyZLA9OnyImR2mQ/edit?usp=sharing
내가 고친 부분엔 ##### 표시를 해뒀다.
원래 소스는 Cartpole 게임을 플레이 하는 소스이다.
우선 받은 소스 위에 앞 글에서 찾아낸 슈퍼마리오 관련 코드를 붙이고
import gym
from gym.envs.registration import register
from gym.scoreboard.registration import add_group
from gym.scoreboard.registration import add_task
register(
id='SuperMarioBros-1-1-v0',
entry_point='gym.envs.ppaquette_gym_super_mario:MetaSuperMarioBrosEnv',
)
add_group(
id='ppaquette_gym_super_mario',
name='ppaquette_gym_super_mario',
description='super_mario'
)
add_task(
id='SuperMarioBros-1-1-v0',
group='ppaquette_gym_super_mario',
summary="SuperMarioBros-1-1-v0"
)게임 이름을 슈퍼마리오로 고쳐준다
env = gym.make('SuperMarioBros-1-1-v0')다음으로 인풋/아웃풋 개수를 맞춰준다
input_size = env.observation_space.shape[0]*env.observation_space.shape[1]*3 output_size = 6
처음에 인풋 갯수가 172032개여서 헉 이게 뭐지! 했는데
스크린 픽셀 개수 가로*세로*3 이다.
ppaquette_gym_super_mario/nes_env.py 에서 정보를 찾을 수 있다.
스크린 픽셀 갯수에 *3이면 RGB 값... 그렇다면...

갑자기 이런게 막 떠오르려고 하는데 우선 넘어가자
소스의 아랫 부분을 보면 원래 이런 부분이 있는데 고쳐줘야 한다.
while not done:
if np.random.rand(1) < e:
action = env.action_space.sample()
else:
# Choose an action by greedily from the Q-network
action = np.argmax(mainDQN.predict(state))
랜덤으로 입력을 받는 부분인 env.action_space.sample() 은 잘 돌아가는데 아래 action 부분이 원래 cartpole 게임에 맞춰져 있다. 이렇게 바꿔야 한다.
action = mainDQN.predict(state).flatten().tolist()
숫자 6개 출력을 받아서 argmax 하지말고 그냥 리스트로 만들어서 주면 된다.드디어 슈퍼마리오를 플레이 해보면, 슈퍼마리오가 한번만 실행되고 에러가 난다.
ddqn_replay_train()에
y_stack = np.vstack([y_stack, Q])
x_stack = np.vstack([x_stack, state])
이 부분의 state가 한줄(array) 형태가 아니고 matrix 여서 vstack을 쓸 수 없다.state를 한줄로 쫙쫙 펴줘야 한다.
y_stack = np.vstack([y_stack, Q])
x_stack = np.vstack([x_stack, state.reshape(-1, mainDQN.input_size)])
그래야 vstack 함수 그대로 쓸 수 있다.여기까지만 고쳐도 실행해보면 슈퍼마리오가 돌아간다. 그런데 꼭 고쳐줘야 하는 부분이 있다.
위에서 아웃풋 크기가 6라고 했는데 무슨 뜻인지는
ppaquette_gym_super_mario/wrappers/action_space.py 에서 찾을 수 있다.
0: [0, 0, 0, 0, 0, 0], # NOOP
1: [1, 0, 0, 0, 0, 0], # Up
2: [0, 0, 1, 0, 0, 0], # Down
3: [0, 1, 0, 0, 0, 0], # Left
4: [0, 1, 0, 0, 1, 0], # Left + A
5: [0, 1, 0, 0, 0, 1], # Left + B
6: [0, 1, 0, 0, 1, 1], # Left + A + B
7: [0, 0, 0, 1, 0, 0], # Right
8: [0, 0, 0, 1, 1, 0], # Right + A
9: [0, 0, 0, 1, 0, 1], # Right + B
10: [0, 0, 0, 1, 1, 1], # Right + A + B
11: [0, 0, 0, 0, 1, 0], # A
12: [0, 0, 0, 0, 0, 1], # B
13: [0, 0, 0, 0, 1, 1], # A + B
그냥 float 6개를 넘기면 되는게 아니라 0 또는 1로 넘겨줘야 하는 것이다.
참고로 이거, float 0.0이나 1.0으로 넘겨도 안된다. 꼭 integer 0이나 1이어야 한다.
이 외의 숫자를 넘기면 슈퍼마리오가 아예 움직이지 않는다.
위에서 그냥 슈퍼마리오를 실행 했을 때 슈퍼마리오가 움직이는건 내가 계산해 낸 출력 때문이 아니라 윗줄의 랜덤 출력
if np.random.rand(1) < e:
action = env.action_space.sample()
때문이다.결과값이 0, 1이라니... 여기에 또 뭘 적용해볼까 막 시그모이... 같은게 떠오르지만,
우선 슈퍼마리오를 실행하는게 목표니까 그냥 이렇게 하자.
for i in range(len(action)):
if action[i] > 0.5 :
action[i] = 1
else:
action[i] = 0
반올림 ㅋ이제 슈퍼마리오를 실행하면 된다.
오~ 된다.
...
그런데 또 잠깐.
반복 실행을 하다보면 인풋이 이상하게 들어와서 에러가 날 때가 있다.
그게 왜 들어오는진 모르겠지만 인풋이 이상하게 들어오면 그 프레임은 무시하고 넘어가자.
우선 ddqn_replay_train()에서 출력만 시키고 다음으로 넘어가자
if state is None:
print("None State, ", action, " , ", reward, " , ", next_state, " , ", done)
else:
원래 함수
랜덤 플레이를 만드는 아래 부분에
if np.random.rand(1) < e:
action = env.action_space.sample()
이렇게 좀 추가하자. 그냥 버그스럽게 이렇게 인풋이 들어올 때가 있다는 것만 기억하고.
if np.random.rand(1) < e or state is None or state.size == 1:
action = env.action_space.sample()
이렇게 하면 드디어 슈퍼마리오가 실행 된다.
(효율 적으로 플레이 된다는 게 아니다. 그냥 에러 없이 실행 된다는 것 뿐)
학습을 하는지 마는지 몰라도 에러 없이 실행되긴 한다.
그냥 랜덤 입력으로 플레이 하는 것도 같지만 계속 켜놓으면 행동이 점점 변하긴 한다.
그게 좋은 쪽으로 변하는건지가 문제지만.
그냥 랜덤 입력으로 플레이 하는 것도 같지만 계속 켜놓으면 행동이 점점 변하긴 한다.
그게 좋은 쪽으로 변하는건지가 문제지만.
최종 코드 파일은 여기:
https://docs.google.com/document/d/16LLmgRPGZF2-wEa57uSbvwhDlnaPgyZLA9OnyImR2mQ/edit?usp=sharing
내가 고친 부분엔 ##### 표시를 해뒀다.
# original DQN 2015 source from https://github.com/nalsil/kimhun_rl_windows/blob/master/07_3_dqn_2015_cartpole.py
# The code is updated to play super mario by Jinman Chang
# super mario game can be downloaded at https://github.com/ppaquette/gym-super-mario
# ##### is marked where is updated
# explanation for this code is at http://jinman190.blogspot.ca/2017/10/rl.html
###############################################################################super mario initialized
import gym
from gym.envs.registration import register
from gym.scoreboard.registration import add_group
from gym.scoreboard.registration import add_task
register(
id='SuperMarioBros-1-1-v0',
entry_point='gym.envs.ppaquette_gym_super_mario:MetaSuperMarioBrosEnv',
)
add_group(
id='ppaquette_gym_super_mario',
name='ppaquette_gym_super_mario',
description='super_mario'
)
add_task(
id='SuperMarioBros-1-1-v0',
group='ppaquette_gym_super_mario',
summary="SuperMarioBros-1-1-v0"
)
#################################################################################
import numpy as np
import tensorflow as tf
import random
from collections import deque
from gym import wrappers
env = gym.make('SuperMarioBros-1-1-v0') #####update game title
# Constants defining our neural network
input_size = env.observation_space.shape[0]*env.observation_space.shape[1]*3 #####change input_size - 224*256*3 acquired from ppaquette_gym_super_mario/nes_env.py
output_size = 6 #####meaning of output can be found at ppaquette_gym_super_mario/wrappers/action_space.py
dis = 0.9
REPLAY_MEMORY = 50000
class DQN:
def __init__(self, session, input_size, output_size, name="main"):
self.session = session
self.input_size = input_size
self.output_size = output_size
self.net_name = name
self._build_network()
def _build_network(self, h_size=10, l_rate=1e-1):
with tf.variable_scope(self.net_name):
self._X = tf.placeholder(tf.float32, [None, self.input_size], name="input_x")
# First layer of weights
W1 = tf.get_variable("W1", shape=[self.input_size, h_size],
initializer=tf.contrib.layers.xavier_initializer())
layer1 = tf.nn.tanh(tf.matmul(self._X, W1))
# Second layer of Weights
W2 = tf.get_variable("W2", shape=[h_size, self.output_size],
initializer=tf.contrib.layers.xavier_initializer())
# Q prediction
self._Qpred = tf.matmul(layer1, W2)
# We need to define the parts of the network needed for learning a policy
self._Y = tf.placeholder(shape=[None, self.output_size], dtype=tf.float32)
# Loss function
self._loss = tf.reduce_mean(tf.square(self._Y - self._Qpred))
# Learning
self._train = tf.train.AdamOptimizer(learning_rate=l_rate).minimize(self._loss)
def predict(self, state):
x = np.reshape(state, [1, self.input_size])
return self.session.run(self._Qpred, feed_dict={self._X: x})
def update(self, x_stack, y_stack):
return self.session.run([self._loss, self._train], feed_dict={self._X: x_stack, self._Y: y_stack})
def replay_train(mainDQN, targetDQN, train_batch):
x_stack = np.empty(0).reshape(0, input_size)
y_stack = np.empty(0).reshape(0, output_size)
# Get stored information from the buffer
for state, action, reward, next_state, done in train_batch:
Q = mainDQN.predic(state)
# terminal?
if done:
Q[0, action] = reward
else:
# get target from target DQN (Q')
Q[0, action] = reward + dis * np.max(targetDQN.predict(next_state))
y_stack = np.vstack([y_stack, Q])
x_stack = np.vstack( [x_stack, state])
# Train our network using target and predicted Q values on each episode
return mainDQN.update(x_stack, y_stack)
def ddqn_replay_train(mainDQN, targetDQN, train_batch):
'''
Double DQN implementation
:param mainDQN: main DQN
:param targetDQN: target DQN
:param train_batch: minibatch for train
:return: loss
'''
x_stack = np.empty(0).reshape(0, mainDQN.input_size)
y_stack = np.empty(0).reshape(0, mainDQN.output_size)
# Get stored information from the buffer
for state, action, reward, next_state, done in train_batch:
if state is None: #####why does this happen?
print("None State, ", action, " , ", reward, " , ", next_state, " , ", done)
else:
Q = mainDQN.predict(state)
# terminal?
if done:
Q[0, action] = reward
else:
# Double DQN: y = r + gamma * targetDQN(s')[a] where
# a = argmax(mainDQN(s'))
# Q[0, action] = reward + dis * targetDQN.predict(next_state)[0, np.argmax(mainDQN.predict(next_state))]
Q[0, action] = reward + dis * np.max(targetDQN.predict(next_state)) #####use normal one for now
y_stack = np.vstack([y_stack, Q])
x_stack = np.vstack([x_stack, state.reshape(-1, mainDQN.input_size)]) #####change shape to fit to super mario
# Train our network using target and predicted Q values on each episode
return mainDQN.update(x_stack, y_stack)
def get_copy_var_ops(*, dest_scope_name="target", src_scope_name="main"):
# Copy variables src_scope to dest_scope
op_holder = []
src_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=src_scope_name)
dest_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=dest_scope_name)
for src_var, dest_var in zip(src_vars, dest_vars):
op_holder.append(dest_var.assign(src_var.value()))
return op_holder
def bot_play(mainDQN, env=env):
# See our trained network in action
state = env.reset()
reward_sum = 0
while True:
env.render()
action = np.argmax(mainDQN.predict(state))
state, reward, done, _ = env.step(action)
reward_sum += reward
if done:
print("Total score: {}".format(reward_sum))
break
def main():
max_episodes = 5000
# store the previous observations in replay memory
replay_buffer = deque()
with tf.Session() as sess:
mainDQN = DQN(sess, input_size, output_size, name="main")
targetDQN = DQN(sess, input_size, output_size, name="target")
tf.global_variables_initializer().run()
#initial copy q_net -> target_net
copy_ops = get_copy_var_ops(dest_scope_name="target", src_scope_name="main")
sess.run(copy_ops)
for episode in range(max_episodes):
e = 1. / ((episode / 10) + 1)
done = False
step_count = 0
state = env.reset()
while not done:
if np.random.rand(1) < e or state is None or state.size == 1: #####why does this happen?
action = env.action_space.sample()
else:
# Choose an action by greedily from the Q-network
#action = np.argmax(mainDQN.predict(state))
action = mainDQN.predict(state).flatten().tolist() #####flatten it and change it as a list
for i in range(len(action)): #####the action list has to have only integer 1 or 0
if action[i] > 0.5 :
action[i] = 1 #####integer 1 only, no 1.0
else:
action[i] = 0 #####integer 0 only, no 0.0
# Get new state and reward from environment
next_state, reward, done, _ = env.step(action)
if done: # Penalty
reward = -100
# Save the experience to our buffer
replay_buffer.append((state, action, reward, next_state, done))
if len(replay_buffer) > REPLAY_MEMORY:
replay_buffer.popleft()
state = next_state
step_count += 1
if step_count > 10000: # Good enough. Let's move on
break
print("Episode: {} steps: {}".format(episode, step_count))
if step_count > 10000:
pass
# break
if episode % 10 == 1: # train every 10 episode
# Get a random batch of experiences
for _ in range(50):
minibatch = random.sample(replay_buffer, 10)
loss, _ = ddqn_replay_train(mainDQN, targetDQN, minibatch)
print("Loss: ", loss)
# copy q_net -> target_net
sess.run(copy_ops)
# See our trained bot in action
env2 = wrappers.Monitor(env, 'gym-results', force=True)
for i in range(200):
bot_play(mainDQN, env=env2)
env2.close()
# gym.upload("gym-results", api_key="sk_VT2wPcSSOylnlPORltmQ")
if __name__ == "__main__":
main()